I should confess upfront: I meant to write this post about four years ago and never got round to it. The tide has turned somewhat towards monorepos now, especially with AI-assisted coding making “grep the whole codebase” more valuable than ever. So this cautionary tale about going multi-repo is perhaps less relevant than it once was.
But still.
A long time ago I worked at a company that traditionally built big monolithic products. Telecoms infrastructure, massive C servers, that sort of thing.
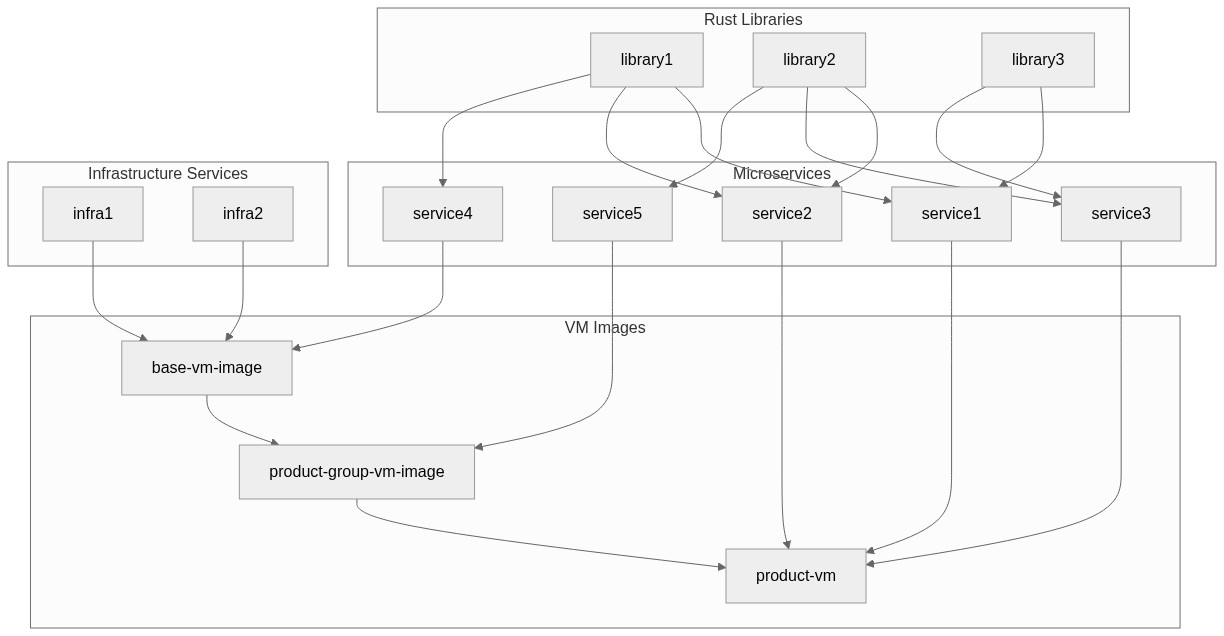
They decided the next generation of products would be different: microservices, containers, Kubernetes. Everyone would share a common language (that’s how I ended up working with Rust), share libraries and frameworks, and compose services in various ways onto VMs built from common base images.
So the setup was: many teams, sharing common libraries, composing microservices in different configurations to make different products, all running on shared infrastructure. Multi-repo felt quite natural for this. People seem to want repos to have clear team ownership. People like small, clean repos. Harder to break abstractions when there’s a repo boundary in the way. A divergence from the monolithic past.
Where It Went Wrong Link to heading
We went too far with it.
You Couldn’t Test Everything Locally Link to heading
There was no easy way to locally test patches of dependencies all the way up the stack. It was manageable enough with the Rust repos - you can use path dependencies and such - but once you hit the microservice boundary, where things shipped in containers, you’d have to build and publish a version of the container to test anything.
You could imagine the scenario: you’ve got a fix for a library, and you want to see if it actually solves the problem in the service that uses it. In a monorepo you’d just… run the service locally with your change. In our setup, you’d have to push your branch, wait for CI to build, publish a dev version of the crate, update the service’s Cargo.toml, push that, wait for its CI to build a container, then finally deploy that container somewhere you could poke at it. By which point you’ve forgotten what you were testing.
Releases Took Days Link to heading
Libraries had to be released, then microservices, then VM images. Especially painful when the change was in a component baked into the VM infrastructure. Long chains of “internal versioned releases” just to ship something to customers.
I was in a group of three teams working on the same product, and each fortnight someone had to volunteer as tribute to spend the best part of a week shepherding the release through. This wasn’t an exaggeration. You’d spend Monday kicking off the library releases. Tuesday you’d be chasing down why some microservice CI had failed. Wednesday you’d be debugging why the VM build was stuck. Thursday you’d realise someone had merged something that broke the integration tests. Friday you’d start over.
We tried automating it, but with CI pipelines deploying and live-testing VMs on a flaky private OpenStack cloud, it could never be reliable enough to not need human intervention. Someone always had to be there to notice the failure, work out if it was a real problem or just flakiness, and decide whether to retry or investigate.
Some Things Could Only Be Tested on Real VMs Link to heading
On the VM infrastructure side we had separate repos for binaries that ran in systemd units on the product VMs. These couldn’t be meaningfully tested outside of an actual VM. The binaries interacted with system services, storage mounts, network configuration - all stuff that didn’t exist in a unit test environment.
It was an endless loop of release candidate builds, or hacking patches onto live VMs just to test something. SSH in, copy the binary over, restart the service, tail the logs, realise you got something wrong, repeat. It worked, but it wasn’t exactly confidence-inspiring.
DRY Made Things Worse Link to heading
There was lots of repeated boilerplate between repos. Every repo needed CI configuration, Docker builds, release workflows, the same linting setup. So we tried to fix this the obvious way: common “CI templates” that repos could pull in like libraries.
It was horrible. The templates became these fragile, over-parameterised monstrosities. Every repo had slightly different needs, so the templates grew conditionals and options until nobody understood them. When something broke, you’d be debugging YAML inheritance across multiple repos. DRY isn’t always the answer.
You Didn’t Know What You Didn’t Know Link to heading
And then there was the problem of not knowing about some repo hidden away somewhere that you might not even have access to. You’d be debugging an issue, following the trail, and suddenly hit a wall because the relevant code was in a repo you’d never heard of, owned by a team you’d never spoken to.
We ended up building something hacky for “cross-repo search” because often the best tool to find the source of an issue is just: grep. If you can’t grep it, you can’t debug it.
The Rule I Came Up With Link to heading
Don’t break up repos beyond the boundary of what you can meaningfully test independently.
If something needs to be released and pulled into another repo before you can test it to an acceptable level, it shouldn’t be in its own repo.
It’s a bit heuristic, but it make sense in my head at least.
Where I Landed Link to heading
My opinion on multi-repo got jaded from this experience. I started out excited about small, single-purpose, easy-to-understand repos. I ended up hating the complexity of the web of how they all fit together.
But I still don’t love monorepos either. They’re big, CI can be slow, and it’s easier to break abstractions when everything’s right there.
The main thing that bothers me is that crappy code and tech debt can propagate inside them. With a multi-repo setup you often “start fresh” when you spin up a new service - you write something that’s up to date with everything you’ve learned from previous projects. In a monorepo it’s easier to perpetuate the patterns in the code around you. You see how the adjacent service does something, you copy it, and now you’ve got two services doing it the old way instead of one.
This is especially true now that LLMs are writing a lot of code. They’re excellent at pattern-matching against what’s already in the repo. If your repo is full of old patterns, they’ll happily reproduce them. The tech debt becomes self-perpetuating.
If I had to choose right now, I’d probably go monorepo. It’s easily grep-able.
But really the “multi vs mono” question isn’t that important. They both have their own special ways of being painful. What matters is your tooling. You can have a monorepo where it’s quick and easy to edit, build, test, and deploy single components or multiple components at once - CI only running for the bits you changed. And you can have a multi-repo setup where the repo boundaries fit how things are actually deployed, tested, and depend on each other at runtime. That’s another reason I lean monorepo these days: picking those boundaries well is hard.
As I said, this is somewhat out of date now. But it’s a true tale of when “going full multi-repo” wasn’t everything it was cracked up to be.
The real message: it’s the tooling that matters, not the choice of mono vs multi.
A note on how this post was written
Disclaimer: I hadn’t posted in this blog for many years mostly because I didn’t get round to it. I had ideas for blog posts, but didn’t find the time to write them out. For a while I also was doing technical blogging on the website for the company I worked for, so got my “technical writing fix” from that. Despite that, I’ve had years at a time where I didn’t write any technical blog, which I regret, as I think it is good for the mind and good for the soul. To kickstart me getting some of my thoughts down on paper again, I’m experimenting with using Claude code to assist me. I’ve tried developing a “skill” by getting it to process all my previous blog and all my writings in Slack to try to capture my “voice”. I’m giving it a stream of conciousness notes and asking it to write that into prose in my voice. So these posts are “written by AI”, but only with ideas I’ve told it to write, and hopefully in my voice. I’ll include at the bottom my raw notes that this article is derived from.
Raw notes this post was derived from: