We All Write Monads, Whether We Know It or Not
Recently I’ve been rebooting my Haskell by working through Advent of Code, and bogging about it:
and it’s got me thinking. I was quickly re-introduced to the concepts of: Functors, Applicative Functors, Monoids, Monads, a strong type system, higher kinded types, and functional purity, and straight away, started spotting these patterns in the code I write every day at work (predominantly Rust with some Bash, Python, and C++ thrown in for good measure).
I find myself thinking about code I’m working with, and saying to myself, or anyone who will listen, things like:
“Ah well, this works because string concatenation behaves monoidally…”
or:
“What we’ve got here is a computational context for our data that we want to map over…”
What this has made me realise is there’s nothing special about Haskell that means these concepts exist where they don’t exist in other languages.
Haskell formalises data manipulation patterns that exist wherever there is data to manipulate.
Have you ever had a “container type” for your data that you’ve iterated over? You’ve used a functor.
Have you ever encoded error handling in the data you’re using? You’ve used something resembling a monad.
Rust’s ownership model is a formalisation of a set of memory management patterns that a C developer might employ to attempt to write memory safe and thread safe code.
Regardless of the language we’re writing in, these data manipulation patterns are there. The language may formalise them, it may not. By formalising data manipulation patterns in a language, there’s the opportunity for the compiler to tell you if you’re using them right, otherwise you’re performing these patterns by hand.
What it comes down to is:
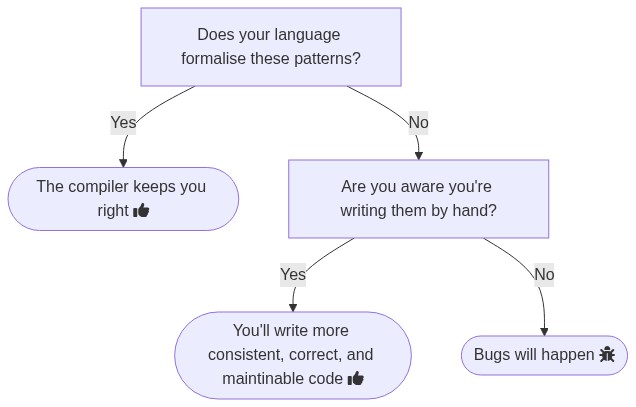
When I first learned some Haskell a few years ago, the idea of spending my free time doing that was sold to me as “it’ll make you better at every other language”. That was enough to sell it to me at the time, and I believe it had that effect. It’s true of every language to some extent. Every language formalises some number of data manipulation patterns, the question is: to what extent? And are they good patterns to be using to get correct and maintainable code?
There is the argument I’ve seen where someone might answer “No” to both of the above, adding “and it doesn’t matter”. I’ve seen claims that learning the concepts that formalise patterns of data manipulation is overly esoteric and not pragmatic. To try to understand these things makes you a “purist”, and gets in the way of “getting things done”. I think the reality is that software, in general, has had growth as a higher priority than quality and correctness for some amount of time. A lot of code can have quite a short shelf life so preference is given to being able to produce code quickly and the negative side effects of that aren’t felt so much. I’m not totally convinced by this position. There’s potential for a feedback loop where the consequences of trying to produce things quickly drive the short shelf lives. And I’m not entirely convinced that languages that do formalize a lot of these patterns and have a compiler that keeps you right on them is generally slower to produce things. There’s learning time that you have to put in, but once you’ve learned to satiate the compiler on your first try, you don’t tend to spend that much time fighting it. There are specific problems that are going to be slower to develop solutions to, but I don’t thing it’s necessarily true generally. There a counter argument that to produce anything of a meaningful size you can produce things faster because the compiler has stopped you hitting things that you would hit and have to address before you were able to ship something. This one probably depends on the problem you’re trying to build a solution to.
Regardless of the relative strengths of those arguments, it’s certainly true that developers have been able to “get away with” not having these patterns formalised and not necessarily knowing they’re hand rolling them. Whether that continues into the future is going to be interesting.
As software becomes more prevalent in all industries, every professional is writing code, and every child learns coding in school (which they already are): I’d wager we’ll see the general quality bar expected by users/consumers to go up, as they’ll have greater visibility into how unnecessary a lot of broken and slow software is. As the systems we’re building are getting more interconnected and complex, is correctness going to become more of a priority?
This isn’t to say that there won’t always be bugs in software. No matter how solid the tools you use are, you could have just missed the mark on requirements and built the wrong thing. But there are whole classes of bugs and errors that can be eliminated by formalising these patterns and encoding them into the fundamental tools with which we build things.
I work with Rust most working days. While it’s missing higher kinded types, it’s got a lot going for it with its strong type system, its ownership model, and generally how it makes you be explicit about what you’re doing. People say with Rust that “if it compiles it works”, and provided you’ve written code that leverages the type system, there’s some truth to that. I might re-phrase that to “if it compiles then what you’ve asked for is guaranteed to be consistent in various ways, but you might still have asked for the wrong thing”, but that’s a little less catchy. It makes me hopeful for the future, and I believe that Rust will stand as one of the cornerstones of a new generation of software that works.